Microarchitecture (architecture des processeurs)
La microarchitecture décrit l'organisation matérielle d'un processeur : composants, flux de données et mécanismes qui implémentent une architecture d'instructions (ISA). Elle influence performances, consommation et coût.
La microarchitecture, souvent abrégée en « µarch » ou « uarch », désigne l'organisation interne d'un processeur ou d'une unité de traitement. Elle précise comment les blocs matériels (unités arithmétiques, registres, caches, contrôleurs) collaborent pour exécuter les instructions définies par une architecture d'instructions (ISA). Plusieurs microarchitectures différentes peuvent implémenter la même ISA, offrant des compromis variés en performances, consommation et complexité.
Galerie d’images
1 Image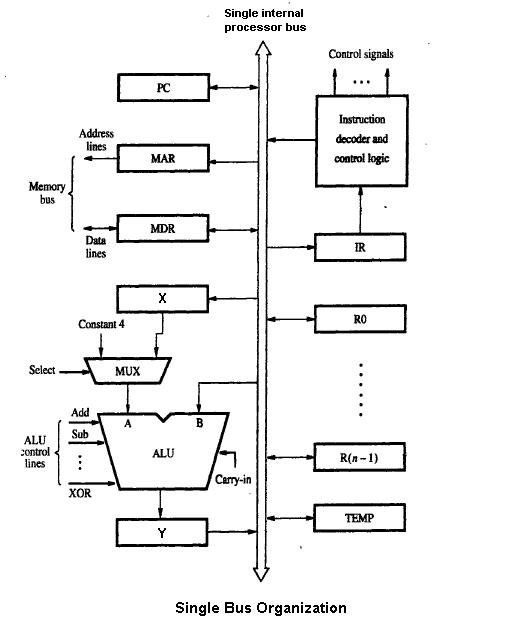
Principaux éléments et rôles
Une microarchitecture comporte plusieurs sous-systèmes essentiels. Parmi eux :
- Chemin de données (datapath) : registres, unités arithmétiques (ALU), unités flottantes (FPU) et multiplexeurs qui effectuent les opérations.
- Unité de contrôle : contrôle séquentiel et logique de commande, parfois microcodée.
- Pipeline : segmentation des étapes d'exécution pour augmenter le débit d'instructions.
- Mécanismes d'optimisation : prédicteurs de branche, buffers d'instructions, exécution out-of-order, réordonnancement, et files d'attente.
- Sous-systèmes mémoire : caches (L1/L2/L3), gestion des accès mémoire, contrôleurs et cohérence pour architectures multi-cœurs.
Évolution historique
Les idées fondatrices datent des premiers ordinateurs et du concept de microprogramme proposé au milieu du XXe siècle pour simplifier la commande matérielle. Par la suite, des avancées telles que le pipeline, le superscalaire et l'exécution hors ordre ont transformé la conception des processeurs en réponse aux besoins croissants de performance. Les mouvements RISC et CISC ont aussi influencé la façon dont on répartit la complexité entre ISA et microarchitecture.
Techniques et stratégies modernes
Les microarchitectures contemporaines combinent souvent plusieurs techniques : décodage et fusion d'instructions, exécution superscalaire pour lancer plusieurs opérations simultanément, algorithmes de réordonnancement dynamique pour résoudre les dépendances, et prédiction de branche sophistiquée pour maintenir l'efficacité du pipeline. Les architectes équilibrent ces éléments avec des contraintes de consommation d'énergie et de surface silicium.
Implémentation, vérification et compromis
Une microarchitecture peut être réalisée en logique standard, en ASIC, ou sur FPGA. La conception exige simulation et vérification poussées afin d'assurer fiabilité et sécurité. Les choix d'architecture impliquent des compromis : performances brutes vs consommation énergétique, complexité du design vs facilité de validation, coût de fabrication vs densité de fonctions.
En résumé, la microarchitecture est la couche matérielle concrète qui met en œuvre une ISA et détermine le comportement réel du processeur. Comprendre ses composants et compromis est essentiel pour analyser les performances, l'efficacité énergétique et l'adaptabilité d'une puce à des usages variés.
Origine du terme
Les ordinateurs utilisent la microprogrammation de la logique de contrôle depuis les années 1950. L'unité centrale décode les instructions et envoie les signaux par des chemins appropriés au moyen de commutateurs à transistor. Les bits à l'intérieur des mots du microprogramme commandent le processeur au niveau des signaux électriques.
Le terme : microarchitecture a été utilisé pour décrire les unités qui étaient contrôlées par les mots du microprogramme, par opposition au terme : "architecture" qui était visible et documentée pour les programmeurs. Alors que l'architecture devait généralement être compatible entre les générations de matériel, la micro-architecture sous-jacente pouvait être facilement modifiée.
Relation avec l'architecture du jeu d'instructions
La micro-architecture est liée à l'architecture du jeu d'instructions, mais elle n'est pas identique à celle-ci. L'architecture du jeu d'instructions est proche du modèle de programmation d'un processeur tel qu'il est vu par un programmeur en langage assembleur ou un auteur de compilateur, qui comprend le modèle d'exécution, les registres du processeur, les modes d'adresse mémoire, les formats d'adresse et de données, etc. La micro-architecture (ou organisation de l'ordinateur) est principalement une structure de niveau inférieur et gère donc un grand nombre de détails qui sont cachés dans le modèle de programmation. Elle décrit les parties internes du processeur et la façon dont elles fonctionnent ensemble afin de mettre en œuvre la spécification architecturale.
Les éléments micro-architecturaux peuvent être de toutes sortes, des portes logiques simples aux registres, tables de recherche, multiplexeurs, compteurs, etc., en passant par des ALU, FPU complètes et même des éléments plus importants. Le niveau des circuits électroniques peut, à son tour, être subdivisé en détails au niveau des transistors, tels que les structures de base de construction des portes utilisées et les types d'implémentation logique (statique/dynamique, nombre de phases, etc.) choisis, en plus de la conception logique réelle utilisée pour les construire.
Quelques points importants :
- Une seule microarchitecture, surtout si elle comprend un microcode, peut être utilisée pour mettre en œuvre de nombreux jeux d'instructions différents, en changeant le magasin de contrôle. Cela peut cependant être assez compliqué, même si cela est simplifié par des structures de microcodes et/ou de tableaux dans les ROM ou les PLA.
- Deux machines peuvent avoir la même micro-architecture, et donc le même schéma fonctionnel, mais des implémentations matérielles complètement différentes. Cela permet de gérer à la fois le niveau du circuit électronique et encore plus le niveau physique de fabrication (des deux circuits intégrés et/ou des composants discrets).
- Les machines ayant des micro-architectures différentes peuvent avoir la même architecture de jeu d'instructions, et donc toutes deux sont capables d'exécuter les mêmes programmes. Les nouvelles micro-architectures et/ou solutions de circuits, ainsi que les progrès dans la fabrication des semi-conducteurs, permettent aux nouvelles générations de processeurs d'atteindre des performances plus élevées.
Descriptions simplifiées
Une description de haut niveau très simplifiée - courante en marketing - peut ne montrer que des caractéristiques assez élémentaires, comme la largeur des bus, ainsi que divers types d'unités d'exécution et d'autres grands systèmes, comme la prédiction de branche et les mémoires cache, représentés sous forme de simples blocs - avec peut-être quelques attributs ou caractéristiques importants notés. Certains détails concernant la structure du pipeline (comme l'extraction, le décodage, l'affectation, l'exécution, la reprise) peuvent parfois aussi être inclus.
Aspects de la micro-architecture
Le chemin de données en pipeline est la conception de chemin de données la plus couramment utilisée dans la microarchitecture aujourd'hui. Cette technique est utilisée dans la plupart des microprocesseurs, microcontrôleurs et DSP modernes. L'architecture en pipeline permet à plusieurs instructions de se chevaucher en cours d'exécution, un peu comme sur une chaîne de montage. Le pipeline comprend plusieurs étapes différentes qui sont fondamentales dans les conceptions de micro-architecture. Certaines de ces étapes comprennent la recherche d'instructions, le décodage d'instructions, l'exécution et la réécriture. Certaines architectures comprennent d'autres étapes telles que l'accès à la mémoire. La conception de pipelines est l'une des tâches centrales de la micro-architecture.
Les unités d'exécution sont également essentielles à la micro-architecture. Les unités d'exécution comprennent les unités arithmétiques et logiques (ALU), les unités à virgule flottante (FPU), les unités de charge/stockage et la prédiction de branche. Ces unités exécutent les opérations ou les calculs du processeur. Le choix du nombre d'unités d'exécution, leur latence et leur débit sont des tâches importantes de la conception microarchitecturale. La taille, la latence, le débit et la connectivité des mémoires au sein du système sont également des décisions microarchitecturales.
Les décisions de conception au niveau du système, telles que l'inclusion ou non de périphériques, comme les contrôleurs de mémoire, peuvent être considérées comme faisant partie du processus de conception microarchitecturale. Cela inclut les décisions relatives au niveau de performance et à la connectivité de ces périphériques.
Contrairement à la conception architecturale, où un niveau de performance spécifique est l'objectif principal, la conception microarchitecturale accorde une attention plus grande aux autres contraintes. Il faut notamment tenir compte des points suivants :
- Surface de la puce/coût.
- Consommation d'énergie.
- Complexité logique.
- Facilité de connectivité.
- La fabricabilité.
- Facilité de débogage.
- Testabilité.
Concepts micro-architecturaux
En général, toutes les unités centrales, les microprocesseurs monopuces ou les implémentations multi-puces exécutent des programmes en suivant les étapes suivantes :
- Lisez une instruction et décodez-la.
- Trouvez toutes les données associées nécessaires au traitement de l'instruction.
- Traiter l'instruction.
- Rédigez les résultats.
Cette série d'étapes d'apparence simple est compliquée par le fait que la hiérarchie de la mémoire, qui comprend la mise en cache, la mémoire principale et le stockage non volatil comme les disques durs (où se trouvent les instructions des programmes et les données) a toujours été plus lente que le processeur lui-même. L'étape (2) introduit souvent un retard (en termes de CPU, souvent appelé "stall") pendant que les données arrivent par le bus de l'ordinateur. De nombreuses recherches ont été menées pour concevoir des systèmes qui évitent autant que possible ces retards. Au fil des ans, un objectif central de la conception a été d'exécuter davantage d'instructions en parallèle, augmentant ainsi la vitesse d'exécution effective d'un programme. Ces efforts ont introduit des structures de logique et de circuit compliquées. Dans le passé, ces techniques ne pouvaient être mises en œuvre que sur des ordinateurs centraux ou des superordinateurs coûteux en raison de la quantité de circuits nécessaires à ces techniques. Avec les progrès de la fabrication des semi-conducteurs, de plus en plus de ces techniques ont pu être mises en œuvre sur une seule puce semi-conductrice.
Ce qui suit est une étude des techniques micro-architecturales qui sont courantes dans les unités centrales modernes.
Instruction Choix de l'ensemble
Le choix de l'architecture du jeu d'instructions à utiliser influe grandement sur la complexité de la mise en œuvre de dispositifs à hautes performances. Au fil des ans, les concepteurs d'ordinateurs ont fait de leur mieux pour simplifier les jeux d'instructions, afin de permettre des mises en œuvre plus performantes en leur faisant gagner du temps et des efforts pour les fonctionnalités qui améliorent les performances plutôt que de les gaspiller dans la complexité du jeu d'instructions.
La conception des jeux d'instructions a progressé à partir des types CISC, RISC, VLIW, EPIC. Les architectures qui traitent du parallélisme des données comprennent les SIMD et les Vecteurs.
Conduite d'instruction
L'une des premières techniques, et la plus puissante, pour améliorer les performances est l'utilisation du pipeline d'instructions. Les premières conceptions de processeurs exécutaient toutes les étapes ci-dessus sur une instruction avant de passer à la suivante. De grandes parties du circuit du processeur étaient laissées inactives à chaque étape ; par exemple, le circuit de décodage des instructions était inactif pendant l'exécution, etc.
Les pipelines améliorent les performances en permettant à un certain nombre d'instructions de passer simultanément dans le processeur. Dans le même exemple de base, le processeur commencerait à décoder (étape 1) une nouvelle instruction alors que la dernière attend des résultats. Cela permettrait à un maximum de quatre instructions d'être "en vol" en même temps, ce qui ferait paraître le processeur quatre fois plus rapide. Bien qu'une instruction prenne autant de temps pour être exécutée (il y a toujours quatre étapes), le processeur dans son ensemble "retire" les instructions beaucoup plus rapidement et peut être exécuté à une vitesse d'horloge beaucoup plus élevée.
Cache
Les améliorations apportées à la fabrication des puces ont permis de placer davantage de circuits sur la même puce, et les concepteurs ont commencé à chercher des moyens de l'utiliser. L'un des moyens les plus courants consistait à ajouter une quantité toujours plus importante de mémoire cache sur la puce. Le cache est une mémoire très rapide, une mémoire à laquelle on peut accéder en quelques cycles par rapport à ce qui est nécessaire pour parler à la mémoire principale. L'unité centrale comprend un contrôleur de cache qui automatise la lecture et l'écriture à partir du cache. Si les données sont déjà dans le cache, elles "apparaissent" simplement, tandis que si elles ne le sont pas, le processeur est "bloqué" pendant que le contrôleur de cache les lit.
Les conceptions RISC ont commencé à ajouter du cache au milieu et à la fin des années 1980, souvent avec seulement 4 Ko au total. Ce nombre a augmenté avec le temps, et les processeurs typiques ont maintenant environ 512 Ko, tandis que les processeurs plus puissants ont 1 ou 2, voire 4, 6, 8 ou 12 Mo, organisés en plusieurs niveaux d'une hiérarchie de mémoire. D'une manière générale, plus de cache signifie plus de vitesse.
Les caches et les pipelines se complètent parfaitement. Auparavant, il n'était pas très judicieux de construire un pipeline capable de fonctionner plus rapidement que la latence d'accès de la mémoire de caisse hors puce. L'utilisation d'une mémoire cache sur puce signifiait qu'un pipeline pouvait fonctionner à la même vitesse que la latence d'accès au cache, c'est-à-dire sur une durée beaucoup plus courte. Cela a permis aux fréquences de fonctionnement des processeurs d'augmenter à un rythme beaucoup plus rapide que celui de la mémoire hors puce.
Prévision de la branche et exécution spéculative
Les décrochages de pipelines et les chasses d'eau dues aux branches sont les deux principaux éléments qui empêchent d'obtenir de meilleures performances grâce au parallélisme des niveaux d'instruction. Entre le moment où le décodeur d'instructions du processeur découvre qu'il a rencontré une instruction de branchement conditionnel et le moment où la valeur du registre de saut décisif peut être lue, le pipeline peut être bloqué pendant plusieurs cycles. En moyenne, une instruction sur cinq exécutée est un branchement, ce qui représente un nombre élevé de blocages. Si la branche est prise, c'est encore pire, car toutes les instructions suivantes qui étaient dans le pipeline doivent être supprimées.
Des techniques telles que la prédiction de branche et l'exécution spéculative sont utilisées pour réduire ces sanctions de branche. La prédiction de branche est le moyen par lequel le matériel fait des suppositions éclairées sur le fait qu'une branche particulière sera prise ou non. La supposition permet au matériel de prélever des instructions sans attendre la lecture du registre. L'exécution spéculative est une autre amélioration dans laquelle le code le long du chemin prédit est exécuté avant que l'on sache si la branche doit être prise ou non.
Exécution hors délai
L'ajout de caches réduit la fréquence ou la durée des blocages dus à l'attente de la récupération des données dans la hiérarchie de la mémoire principale, mais ne permet pas de se débarrasser entièrement de ces blocages. Dans les premières conceptions, un échec de la mémoire cache obligeait le contrôleur de la mémoire cache à bloquer le processeur et à attendre. Bien sûr, il peut y avoir d'autres instructions dans le programme dont les données sont disponibles dans le cache à ce moment-là. L'exécution hors service permet de traiter cette instruction prête à l'emploi pendant qu'une instruction plus ancienne attend dans la mémoire cache, puis de réordonner les résultats pour faire croire que tout s'est passé dans l'ordre programmé.
Superscalar
Malgré toute la complexité et les portes supplémentaires nécessaires pour soutenir les concepts décrits ci-dessus, les améliorations dans la fabrication des semi-conducteurs ont rapidement permis d'utiliser encore plus de portes logiques.
Dans le schéma ci-dessus, le processeur traite des parties d'une seule instruction à la fois. Les programmes informatiques pourraient être exécutés plus rapidement si plusieurs instructions étaient traitées simultanément. C'est ce que les processeurs superscalaires réalisent, en reproduisant des unités fonctionnelles telles que les ALU. La réplication des unités fonctionnelles n'a été rendue possible que lorsque la zone du circuit intégré (parfois appelée "matrice") d'un processeur à émission unique ne dépassait plus les limites de ce qui pouvait être fabriqué de manière fiable. À la fin des années 1980, les conceptions superscalaires ont commencé à faire leur apparition sur le marché.
Dans les conceptions modernes, il est courant de trouver deux unités de charge, une unité de stockage (de nombreuses instructions n'ont pas de résultats à stocker), deux unités mathématiques entières ou plus, deux unités à virgule flottante ou plus, et souvent une unité SIMD d'une certaine sorte. La logique d'émission des instructions devient de plus en plus complexe en lisant une énorme liste d'instructions en mémoire et en les transmettant aux différentes unités d'exécution qui sont inactives à ce moment-là. Les résultats sont ensuite collectés et réordonnés à la fin.
Renommer le registre
Le renommage des registres fait référence à une technique utilisée pour éviter l'exécution en série inutile d'instructions de programme en raison de la réutilisation des mêmes registres par ces instructions. Supposons que nous ayons des groupes d'instructions qui utiliseront le même registre, un ensemble d'instructions est exécuté en premier pour laisser le registre à l'autre ensemble, mais si l'autre ensemble est affecté à un registre similaire différent, les deux ensembles d'instructions peuvent être exécutés en parallèle.
Multitraitement et multithreading
En raison de l'écart croissant entre les fréquences de fonctionnement du CPU et les temps d'accès aux DRAM, aucune des techniques qui améliorent le parallélisme au niveau des instructions (ILP) dans un programme ne pouvait surmonter les longs blocages (retards) qui se produisaient lorsqu'il fallait récupérer des données dans la mémoire principale. De plus, le nombre important de transistors et les fréquences de fonctionnement élevées nécessaires aux techniques ILP plus avancées nécessitaient des niveaux de dissipation de puissance qui ne pouvaient plus être refroidis à moindre coût. Pour ces raisons, les nouvelles générations d'ordinateurs ont commencé à utiliser des niveaux de parallélisme plus élevés qui existent en dehors d'un seul programme ou fil de programme.
Cette tendance est parfois connue sous le nom de "calcul à haut débit". Cette idée est née sur le marché des ordinateurs centraux où le traitement des transactions en ligne mettait l'accent non seulement sur la vitesse d'exécution d'une transaction, mais aussi sur la capacité à traiter un grand nombre de transactions en même temps. Les applications basées sur les transactions, telles que le routage en réseau et la desserte de sites web, ayant fortement augmenté au cours de la dernière décennie, l'industrie informatique a de nouveau mis l'accent sur les questions de capacité et de débit.
L'une des techniques permettant d'atteindre ce parallélisme est le recours à des systèmes multiprocesseurs, c'est-à-dire des systèmes informatiques dotés de plusieurs unités centrales. Autrefois, cette technique était réservée aux ordinateurs centraux haut de gamme, mais aujourd'hui, les serveurs multiprocesseurs à petite échelle (2 à 8) sont devenus monnaie courante pour le marché des petites entreprises. Pour les grandes entreprises, les multiprocesseurs à grande échelle (16-256) sont courants. Même les ordinateurs personnels équipés de plusieurs processeurs sont apparus depuis les années 1990.
Les progrès de la technologie des semi-conducteurs ont permis de réduire la taille des transistors ; des processeurs multicœurs sont apparus lorsque plusieurs processeurs sont mis en œuvre sur une même puce de silicium. Initialement, les puces intégrées étaient destinées aux marchés de l'embarqué, où des processeurs plus simples et plus petits permettaient de faire tenir plusieurs instanciations sur une seule pièce de silicium. En 2005, la technologie des semi-conducteurs a permis de fabriquer en volume des puces CMP à double CPU haut de gamme pour ordinateurs de bureau. Certaines conceptions, telles que UltraSPARC T1, utilisaient une conception plus simple (scalaire, en ordre) afin de faire tenir plus de processeurs sur une seule pièce de silicium.
Récemment, une autre technique qui est devenue plus populaire est le multithreading. Dans le cas du multithreading, lorsque le processeur doit aller chercher des données dans une mémoire système lente, au lieu de temporiser pour que les données arrivent, le processeur passe à un autre programme ou à un autre thread de programme qui est prêt à s'exécuter. Bien que cela n'accélère pas un programme/thread particulier, cela augmente le débit global du système en réduisant le temps d'inactivité du CPU.
Conceptuellement, le multithreading est équivalent à un changement de contexte au niveau du système d'exploitation. La différence est qu'un CPU multithreading peut effectuer un changement de thread en un seul cycle de CPU au lieu des centaines ou milliers de cycles de CPU qu'un changement de contexte nécessite normalement. Ceci est réalisé en répliquant le matériel d'état (tel que le fichier de registre et le compteur de programme) pour chaque thread actif.
Une autre amélioration est le multithreading simultané. Cette technique permet à des unités centrales superscalaires d'exécuter simultanément des instructions provenant de différents programmes/threads dans le même cycle.
Pages connexes
- Microprocesseur
- Microcontrôleur
- Processeur multi-cœur
- Processeur de signaux numériques
- Conception du CPU
- Datapath
- le parallélisme des niveaux d'instruction (ILP)
Questions et réponses
Q : Qu'est-ce que la microarchitecture ?
R : La microarchitecture est une description du circuit électrique d'un ordinateur, d'une unité centrale de traitement ou d'un processeur de signaux numériques qui est suffisante pour décrire complètement le fonctionnement du matériel.
Q : Comment les universitaires se réfèrent-ils à ce concept ?
R : Les universitaires utilisent le terme "organisation informatique" lorsqu'ils font référence à la microarchitecture.
Q : Comment les personnes de l'industrie informatique se réfèrent-elles à ce concept ?
R : Les personnes de l'industrie informatique utilisent plus souvent le terme "microarchitecture" lorsqu'elles font référence à ce concept.
Q : Quels sont les deux domaines qui composent l'architecture informatique ?
R : La microarchitecture et l'architecture du jeu d'instructions (ISA) constituent ensemble le domaine de l'architecture informatique.
Q : Que signifie l'abréviation ISA ?
R : ISA est l'abréviation de Instruction Set Architecture.
Q : Que signifie l'abréviation µArch ? R : µArch est l'abréviation de Microarchitecture.
Articles liés
Auteur
AlegsaOnline.com Microarchitecture (architecture des processeurs) Leandro Alegsa
URL: https://fr.alegsaonline.com/art/64586
Sources
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture