Processeur superscalaire
La conception d'un processeur superscalaire permet une forme de calcul parallèle appelée parallélisme au niveau des instructions à l'intérieur d'un seul processeur, ce qui permet de travailler davantage à la même fréquence d'horloge. Cela signif…
La conception d'un processeur superscalaire permet une forme de calcul parallèle appelée parallélisme au niveau des instructions à l'intérieur d'un seul processeur, ce qui permet de travailler davantage à la même fréquence d'horloge. Cela signifie que l'unité centrale exécute plus d'une instruction au cours d'un cycle d'horloge en exécutant plusieurs instructions en même temps (appelé dispatching d'instructions) sur des unités fonctionnelles doubles. Chaque unité fonctionnelle n'est qu'une ressource d'exécution à l'intérieur du noyau de l'unité centrale, comme une unité arithmétique et logique (UAL), une unité à virgule flottante (UFP), un décaleur de bits ou un multiplicateur.
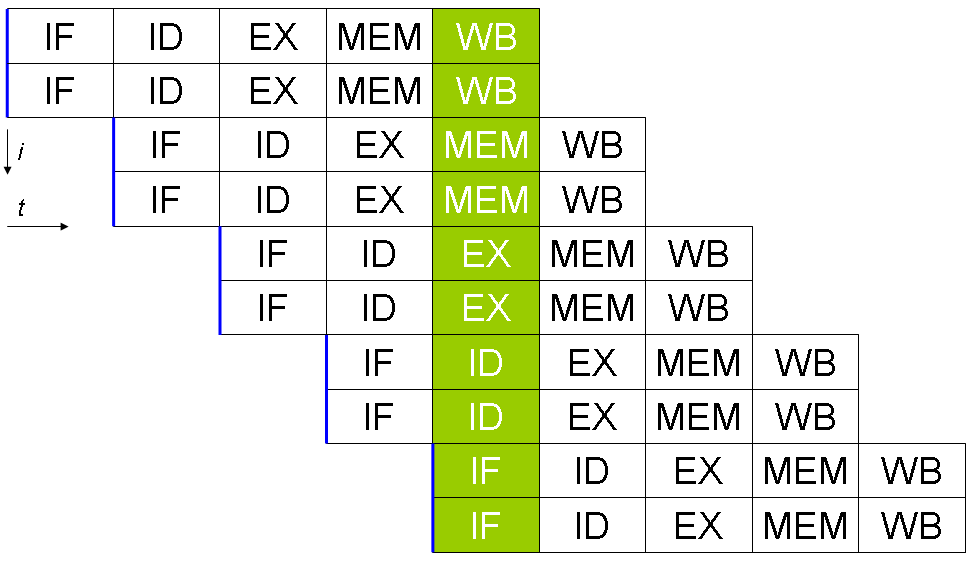
La plupart des CPU superscalaires sont également en pipeline, mais il est possible d'avoir un CPU superscalaire non en pipeline ou un CPU non superscalaire en pipeline.
La technique superscalaire est soutenue par plusieurs caractéristiques du cœur du processeur :
- Les instructions proviennent d'une liste d'instructions ordonnées.
- Le matériel de l'unité centrale peut déterminer quelles instructions ont quelles dépendances de données.
- Peut lire plusieurs instructions par cycle d'horloge
Chaque instruction exécutée par un processeur scalaire modifie un ou deux éléments de données à la fois, mais chaque instruction exécutée par un processeur vectoriel traite plusieurs éléments de données à la fois. Un processeur superscalaire est un mélange des deux :
- Chaque instruction traite un élément de données.
- Il y a plusieurs unités fonctionnelles en double à l'intérieur de chaque noyau de CPU, de sorte que plusieurs instructions traitent des éléments de données indépendants en même temps.
Dans une unité centrale superscalaire, un répartiteur d'instructions lit les instructions en mémoire et décide lesquelles peuvent être exécutées en parallèle, en les répartissant sur les multiples unités fonctionnelles en double disponibles à l'intérieur de l'unité centrale.
La conception de l'unité centrale superscalaire vise à améliorer la précision du répartiteur d'instructions et à lui permettre de maintenir les multiples unités fonctionnelles occupées en permanence. Depuis 2008, toutes les unités centrales à usage général sont superscalaires, une unité centrale superscalaire typique peut comprendre jusqu'à 4 ALU, 2 FPU et deux unités SIMD. Si le répartiteur ne peut pas garder toutes les unités occupées, la performance de l'unité centrale sera moindre.
Galerie d’images
2 Images


Limitations
L'amélioration des performances de la conception des processeurs superscalaires est limitée par deux choses :
- Le niveau de parallélisme intégré dans la liste d'instructions
- La complexité et le coût en temps du dispatcher et de la vérification de la dépendance des données.
Même en vérifiant les dépendances de manière infiniment rapide à l'intérieur d'un CPU superscalaire normal, si la liste d'instructions elle-même comporte de nombreuses dépendances, cela limiterait également l'amélioration possible des performances, de sorte que le degré de parallélisme intégré dans le code constitue une autre limitation.
Quelle que soit la vitesse du dispatcheur, il existe une limite pratique au nombre d'instructions pouvant être envoyées simultanément. Bien que les progrès du matériel permettent d'utiliser davantage d'unités fonctionnelles (par exemple, des ALU) par noyau de CPU, le problème de la vérification des dépendances des instructions augmente à un point tel que la limite de répartition superscalaire réalisable est quelque peu réduite. -- Probablement de l'ordre de cinq à six instructions envoyées simultanément.
Alternatives
- Le multithreading simultané : souvent abrégé en SMT, est une technique permettant d'améliorer la vitesse globale des CPU superscalaires. Le SMT permet d'exécuter plusieurs threads indépendants afin de mieux utiliser les ressources disponibles à l'intérieur d'un processeur superscalaire moderne.
- Processeurs multicœurs : les processeurs superscalaires diffèrent des processeurs multicœurs en ce que les multiples unités fonctionnelles redondantes ne sont pas des processeurs entiers. Un seul processeur superscalaire est composé d'unités fonctionnelles avancées telles que l'ALU, le multiplicateur d'entier, le décaleur d'entier, l'unité à virgule flottante (FPU), etc. Il peut y avoir plusieurs versions de chaque unité fonctionnelle pour permettre l'exécution de nombreuses instructions en parallèle. Il peut y avoir plusieurs versions de chaque unité fonctionnelle pour permettre l'exécution de nombreuses instructions en parallèle. Cela diffère d'un processeur multi-coeurs qui traite simultanément les instructions de plusieurs threads, un thread par cœur.
- Processeurs en pipeline : les processeurs superscalaires diffèrent également d'une unité centrale en pipeline, où les multiples instructions peuvent se trouver simultanément à différents stades d'exécution.
Les diverses techniques alternatives ne s'excluent pas mutuellement : elles peuvent être (et sont souvent) combinées dans un seul processeur, de sorte qu'il est possible de concevoir un CPU multicœur où chaque cœur est un processeur indépendant avec plusieurs pipelines superscalaires parallèles. Certains processeurs multicœurs ont également une capacité vectorielle.
Pages connexes
- Le calcul parallèle
- Parallélisme au niveau de l'enseignement
- Multithreading simultané (SMT)
- Processeurs multicœurs
Questions et réponses
Q : Qu'est-ce que la technologie superscalaire ?
R : La technologie superscalaire est une forme de calcul parallèle de base qui permet de traiter plus d'une instruction par cycle d'horloge en utilisant plusieurs unités d'exécution en même temps.
Q : Comment fonctionne la technologie superscalaire ?
R : La technologie superscalaire implique que les instructions arrivent dans le processeur dans l'ordre, qu'elles recherchent des dépendances de données pendant leur exécution et qu'elles chargent plus d'une instruction par cycle d'horloge.
Q : Quelle est la différence entre les processeurs scalaires et vectoriels ?
R : Sur un processeur scalaire, les instructions travaillent généralement avec un ou deux éléments de données à la fois, tandis que sur un processeur vectoriel, les instructions travaillent généralement avec de nombreux éléments de données à la fois. Un processeur superscalaire est un mélange des deux, car chaque instruction traite une donnée, mais plus d'une instruction s'exécute en même temps, de sorte que le processeur traite plusieurs données à la fois.
Q : Quel rôle joue un distributeur d'instructions précis dans un processeur superscalaire ?
R : Un distributeur d'instructions précis est très important pour un processeur superscalaire, car il garantit que les unités d'exécution sont toujours occupées par le travail qui sera probablement nécessaire. Si le distributeur d'instructions n'est pas précis, il se peut qu'une partie du travail doive être rejetée, ce qui ne rendrait pas le processeur plus rapide qu'un processeur scalaire.
Q : En quelle année tous les processeurs normaux sont-ils devenus superscalaires ?
R : Tous les processeurs normaux sont devenus superscalaires en 2008.
Q : Combien d'ALU, de FPU et d'unités SIMD peut-on trouver sur un processeur normal ?
R : Une unité centrale normale peut comporter jusqu'à 4 UAL, 2 FPU et 2 unités SIMD.
Articles liés
Auteur
AlegsaOnline.com Processeur superscalaire Leandro Alegsa
URL: https://fr.alegsaonline.com/art/95080